

前篇:Pytorch实现广义回归神经网络GRNN – KAKO Academy of Sciences (kakosci.com)
使用的过程中渐渐发现原本的代码有个重大缺陷,那就是不能批量预测()只能用循环把样本一个一个塞进模型,不仅丑陋而且效率非常低下,要预测的样本量一上来就得跑半天。其实一开始也想做批量输入但技术上不知道怎么用张量广播来完成某种运算因此不了了之,后来深入学习了下Broadcast才终于明白要怎么做……
直接引入问题,现有一个训练输入样本的矩阵\(t\),形状为\((n,p)\),即n个特征数为p的样本;再有一个测试输入样本矩阵\(x\),形状为\((m,p)\)。按照原本的算法,我会把测试样本拆成m个,然后分别与整个训练input矩阵进行高斯运算(Gauss即公式\(exp(-\frac{D_i^2}{2\sigma^2})\),\(D\)代表两个样本间的欧氏距离)并得到m个长度为n的一维向量,即高斯层的输出。现在若想要改为使用整个矩阵x和矩阵t直接广播运算并得到形状为\((m,n)\)的输出矩阵,要怎么办?

答案是维度扩张,上图乍一看像是矩阵乘法(如果转置矩阵t),也确实类似,因为矩阵乘法也可以用同样的原理复现。两个张量符合一定要求便可以进行广播计算,简单来说就是首先在张量t的第0维处增加一个维度,使其形状变为\((1,n,p)\),再给张量x的第一维处也增加一个维度,形状变为\((m,1,p)\),再对两个矩阵进行基本的四则运算,所输出的矩阵形状一定为\((m,n,p)\),再对第二维度(即形状中p所在的维度)求和、求最大最小值或求平均等方式降维(分情况使用),就能得到形状为\((m,n)\)的张量。
关于广播机制可参考文章: Numpy学习——广播机制理解 – 知乎 (zhihu.com),torch的广播机制(broadcast mechanism) – 知乎 (zhihu.com) ,下面是高斯层的新代码,把高斯函数分解成了几步来做。
class GaussLayer(nn.Module):
def __init__(self, training_inputs, sigma):
super(GaussLayer, self).__init__()
self.training_inputs = training_inputs.unsqueeze(0) # Turn (n, p) to (1, n, p)
self.sigma = sigma # smoothing parameter
def forward(self, x):
# x: tensor (Matrix) : (m, p)
uns_x = x.unsqueeze(1) # Turn (m, p) to (m, 1, p)
out = uns_x - self.training_inputs # shape: (m, n, p)
out = (out ** 2).sum(dim=2)
out = - out / (2 * self.sigma ** 2)
out = torch.exp(out)
# shape of output: (m, n)
return out到求和层更离谱的事情就发生了,此时求和层的输入变为了前一步得到的矩阵g,形状为\((m,n)\),需要与形状为\((n,k)\)的训练标签矩阵计算得到结果矩阵o(形状\((m,k)\))(具体运算过程见前篇)。按照同样的维度扩张思路,先把两个矩阵分别扩张为\((m,n,1)\)和\((1,n,k)\),进行算数乘法的操作得到形状为\((m,n,k)\)的结果,最后对中间维度求和即可。然而上述操作刚好跟矩阵乘法等价……所以我说矩阵乘法可以用同样的原理复现。因此该层的代码能用@ 运算符直接完成。
class SumAndOutputLayer(nn.Module):
def __init__(self, training_outputs):
super(SumAndOutputLayer, self).__init__()
self.training_outputs = training_outputs
def forward(self, x):
s0 = x.sum(dim=1).unsqueeze(1)
out = (x @ self.training_outputs) / s0
return out进行了上述修改后模型就能批量输入测试样本了,并行运算使代码明显快了很多,耶。附跑数据集的调参曲线和对比验证散点图(决定系数好高,太好了)。
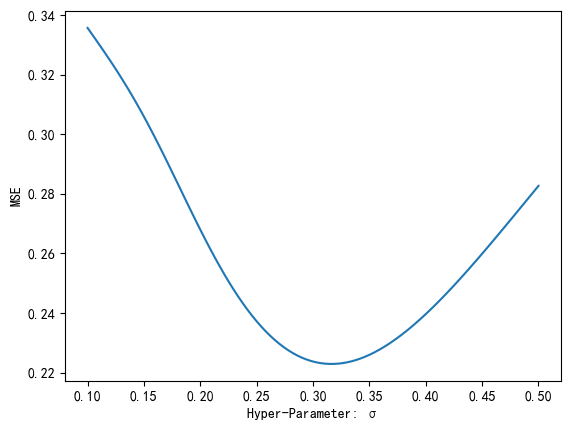
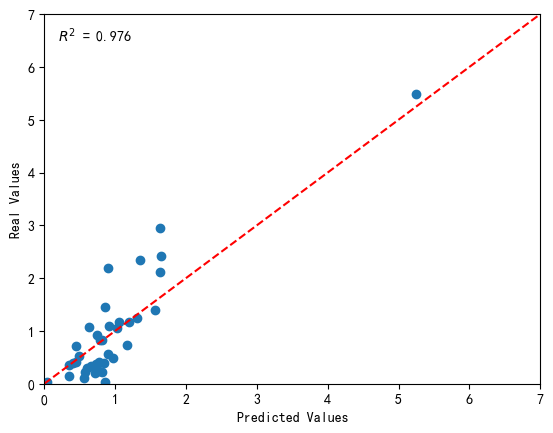
然后是最终的代码,包含了标准化和反标准化,以及开启cuda和转移数据到显卡上的步骤。
"""
Author: kageyamaRik
Creation date: 2023/10/26
Multidimensional input/output feature
Batch prediction
"""
import torch
from torch import nn
class GaussLayer(nn.Module):
def __init__(self, training_inputs, sigma):
super(GaussLayer, self).__init__()
self.training_inputs = training_inputs.unsqueeze(0) # Turn (n, p) to (1, n, p)
self.sigma = sigma # smoothing parameter
def forward(self, x):
# x: tensor (Matrix) : (m, p)
uns_x = x.unsqueeze(1) # Turn (m, p) to (m, 1, p)
out = uns_x - self.training_inputs # shape: (m, n, p)
out = (out ** 2).sum(dim=2)
out = - out / (2 * self.sigma ** 2)
out = torch.exp(out)
# shape of output: (m, n)
return out
class SumAndOutputLayer(nn.Module):
def __init__(self, training_outputs):
super(SumAndOutputLayer, self).__init__()
self.training_outputs = training_outputs
def forward(self, x):
s0 = x.sum(dim=1).unsqueeze(1)
out = (x @ self.training_outputs) / s0
return out
class GRNN:
def __init__(self):
self.t = None # training samples (INPUT)
self.y = None # training samples (OUTPUT)
self.sigma = None # smoothing parameter
self.t_mean = None # mean of each feature (INPUT)
self.t_std = None # std of each feature (INPUT)
self.y_mean = None # mean of each feature (OUTPUT)
self.y_std = None # std of each feature (OUTPUT)
self.net = None # General Regression Neural Network
self.device = None # cpu/cuda
def fit(self, t_samples, y_samples, sigma):
self.device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
self.t = t_samples
self.y = y_samples
self.sigma = sigma
self.t_mean = self.t.mean(dim=0)
self.t_std = self.t.std(dim=0)
self.y_mean = self.y.mean(dim=0)
self.y_std = self.y.std(dim=0)
# Normalization
self.t = (self.t - self.t_mean) / self.t_std
self.y = (self.y - self.y_mean) / self.y_std
self.t = self.t.to(device=self.device)
self.y = self.y.to(device=self.device)
self.sigma = self.sigma.to(device=self.device)
self.net = nn.Sequential(
GaussLayer(self.t, self.sigma),
SumAndOutputLayer(self.y)
)
self.net = self.net.to(device=self.device)
def predict(self, x):
x = (x - self.t_mean) / self.t_std
x = x.to(device=self.device)
out = self.net(x)
out = out.to(device=torch.device('cpu'))
out = out * self.y_std + self.y_mean
return out
记录下加深印象,但写得好乱噢,自己都要看晕了()


呜哇,别教我了直接塞我脑子里
呜哇 快更新你的mod